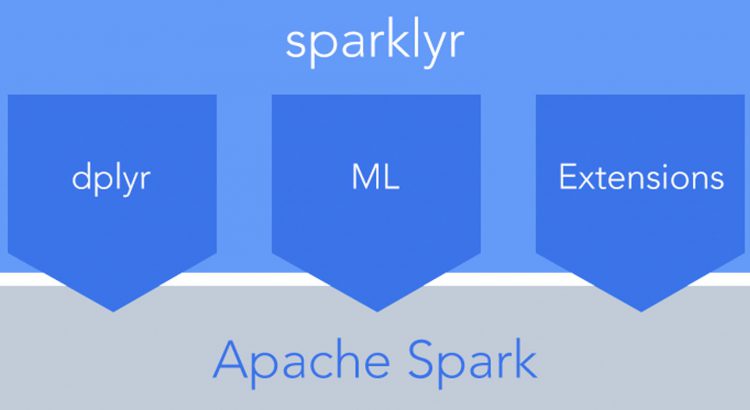
If you haven’t heard of Apache Spark yet, I’d be pretty surprised. It’s an amazing open source project that’s changing the way people think about processing big data. That said, in my opinion it has never been super accessible to those of us data enthusiasts who aren’t Java application engineers – that is until now. Enter sparklyr – a really cool R library put together by the geniuses over at RStudio.
At a high level, sparklyr is a dplyr-like interface for Spark. If you’ve never used dplyr – it’s a very nice, clean way to manipulate data frames in R. dplyr is pretty easy to learn, and you can read all about it here. The problem with dplyr is that it is limited to working on normal R data frames, which have to fit into your machine’s memory (not big data friendly obviously). sparklyr on the other hand allows you to use a dplyr interface, but it basically translates your dplyr statements into Spark SQL statements behind the scenes. This essentially allows you to operate on datasets within R that were previously inaccessible to R analysis!
So, how do you set it up?
First, if you haven’t installed RStudio (my favorite R IDE), I’d highly recommend it – you can get that here. Next, install the sparklyr package like you would any other R library:
# Install the sparklyr package
> install.packages("sparklyr")
# Now load the library
> library(sparklyr)
Now if you’re like me, you may not have easy access to a Spark cluster all the time, which might make sparklyr pretty hard to get started with, but they’ve cleverly added some functions to the library to install a local spark cluster right on your machine for you. This is especially nice for folks like me who don’t really want to deeply manage their own Spark setup.
Note: Before you run this, make sure to update your Java version to the latest (version 8 as of writing this) or you might run into problems later when you try to connect to your local spark instance.
# Install Spark to your local machine > spark_install(version = "2.1.0")
I also recommend installing the latest updated version of sparklyr in order to get the latest fixes/updates/features:
# Install latest version of sparklyr
> devtools::install_github("rstudio/sparklyr")Once you’ve got everything installed, it’s time to connect R to your Spark instance, which you can do like this:
# Connect to Spark
> sc = spark_connect(master = "local")
Once connected successfully, the sc object will be the thing you use to reference your Spark cluster later with sparklyr. Now with all of that setup, you can start loading data and transforming it. For example, if I want to load a bunch of Adobe Analytics data feed files into my Spark cluster, I can use the spark_read_csv function to do that:
# Load the month of Jun 2016 from my data feed files into Spark
> data_feed_local = spark_read_csv(sc=sc, name="data_feed",
path="01-report.suite_2016-06-*.tsv", header=FALSE, delimiter="\t")
From there, you can start doing all of your dplyr commands on the data feed to munge and merge and summarise to your heart’s content. Check back for my next blog post outlining how to actually process and aggregate Adobe Analytics data feeds using sparklyr to do some really neat stuff.
Good luck!