
In my last post, I illustrated methods for implementing rules-based multi-touch attribution models (such as first touch, last touch, linear, half-life time decay, and U-shaped) using Adobe Analytics Data Feeds, Apache Spark, and R. These models are indeed useful and appealing for analyzing the contribution any marketing channel has to overall conversions. However, they all share a common problem: they’re heuristic – meaning at the end of the day, a human being is still left guessing at marketing performance without any real data to back those guesses.
In this (rather long) post, I’m going to show you two ways to take heuristics out of the equation and let the data do the driving – allowing statistical models to determine the distribution of conversions among marketing channels. There are many schools of thought when it comes to algorithmic attribution, but for this post, I’m going to focus in on the two most popular and most widely hailed approaches: the Shapley value method and the Markov chain method.
A bit of history: The Shapley value approach to marketing attribution is derived from a concept of cooperative game theory, and is named after Nobel Laureate Lloyd Shapley. At a high level, the Shapley value is an ingenious solution that solves the problem of equitably distributing the payoff of a game among players who may have an unequal contribution to that payoff (which is similar to distributing credit for an online conversion among marketing channels). The Shapley value is the solution used by Google Analytics’ Data-Driven Attribution model, and variations on the Shapley value approach are used by most attribution and ad bidding vendors in the market today.
The Markov chain method for marketing attribution, on the other hand, has gained a lot of popularity among the data science community and is based on the concept of a Markov chain (named after the brilliant Russian mathematician Andrey Markov). A Markov process makes predictions based on movement through the states of a stochastic process. In a marketing context, this means a visitor’s propensity to convert changes as he/she is exposed to various marketing channels over time. Those differences in propensity provide a great way to measure the influence each marketing channel has on overall conversion.
So, before we launch into each of these approaches, you’ll want to familiarize yourself with some of my previous blog posts as I’ll be relying heavily on them moving forward:
- How to Setup sparklyr: An R Interface for Apache Spark
- How to Setup Adobe Analytics Data Feeds
- How to Use Classifications With Adobe Analytics Data Feeds and R
- Multi-Touch Attribution Using Adobe Analytics Data Feeds and R
With these as a background, I’m going to assume you’ve already loaded your clickstream logs into a sparklyr data frame called “data_feed_tbl” with columns containing your marketing touch points and a conversion indicator (in my case these are called “mid_campaign” and “conversion” respectively). Also, as I’ve previously covered, the next step is to create an order sequence column that we’ll use to group by for our attribution models to work:
# Construct conversions sequences for all visitors data_feed_tbl = data_feed_tbl %>% group_by(visitor_id) %>% arrange(hit_time_gmt) %>% mutate(order_seq = ifelse(conversion > 0, 1, NA)) %>% mutate(order_seq = lag(cumsum(ifelse(is.na(order_seq), 0, order_seq)))) %>% mutate(order_seq = ifelse((row_number() == 1) & (conversion > 0), -1, ifelse(row_number() == 1, 0, order_seq))) %>% ungroup()
In my previous post, I included a step to blank out (using NAs) any sequences that didn’t contain a conversion, but in this case, I won’t do that because we need the non-converting paths to help inform the algorithmic models. With the data prepared, we can now get into the fun part – algorithmic attribution.
The Shapley Value Method
The Shapley value method relies on the marginal contribution of each marketing channel to weight its contribution to overall conversion. Rather than going into all of the gory details here, I recommend reading this very instructive article by Michael Sweeney which explains how marginal contributions work and how you’d calculate them manually using a simple example. However, to make this work at scale, we’re first going to calculate the Shapley value for each possible combination of marketing channels that might have participated in any given order, and to do that, we’ll have to first summarize each of the converting or non-converting sequences according to the marketing channels that participated:
# Summarizing Order Sequences seq_summaries = data_feed_tbl %>% group_by(visitor_id, order_seq) %>% summarize( email_touches = max(ifelse(mid_campaign == "Email",1,0)), natural_search_touches = max(ifelse(mid_campaign == "Natural_Search",1,0)), affiliate_touches = max(ifelse(mid_campaign == "Affiliates",1,0)), paid_search_touches = max(ifelse(mid_campaign == "Paid_Search",1,0)), display_touches = max(ifelse(mid_campaign == "Display",1,0)), social_touches = max(ifelse(mid_campaign == "Social_Media",1,0)), conversions = sum(conversion) ) %>% ungroup()
This bit of code gives us a big binary data frame where each conversion sequence is summarized according to the marketing channels involved (in my case, Email, Natural Search, Affiliates, Paid Search, Display, and Social Media). Since Shapley values aren’t concerned with the number of times the channel participated within a sequence, I use the “max” function rather than a “sum” function since the max value will always be “1” if a sequence converted and “0” if it did not. From there, I need to do one more summarization step to aggregate the total number of sequences and conversions that we observed from each marketing channel combination:
# Sum up the number of sequences and conversions # for each combination of marketing channels conv_rates = seq_summaries %>% group_by(email_touches, natural_search_touches, affiliate_touches, paid_search_touches, display_touches, social_touches) %>% summarize( conversions = sum(conversions), total_sequences = n() ) %>% collect()
For the next part of this analysis, I’m going to rely on a handy R library, “GameTheoryAllocation” which has a fantastic implementation of the Shapley value calculation. As a side note, this is why I love R compared to other languages – there’s almost always a library for any cool algorithm you want to try.
The “GameTheoryAllocation” library requires a characteristic function as input – basically, a vector denoting the payoff (in our case, the conversion rate) received by each possible combination of marketing channels. To get the correct characteristic function, I’ll left join my previous results with the output of the “coalitions” function (a function provided by “GameTheoryAllocation”).
library(GameTheoryAllocation)
number_of_channels = 6
# The coalitions function is a handy function from the GameTheoryALlocation
# library that creates a binary matrix to which you can fit your
# characteristic function (more on this in a bit)
touch_combos = as.data.frame(coalitions(number_of_channels)$Binary)
names(touch_combos) = c("Email","Natural_Search","Affiliates",
"Paid_Search","Display","Social_Media")
# Now I'll join my previous summary results with the binary matrix
# the GameTheoryAllocation library built for me.
touch_combo_conv_rate = left_join(touch_combos, conv_rates,
by = c(
"Email"="email_touches",
"Natural_Search" = "natural_search_touches",
"Affiliates" = "affiliate_touches",
"Paid_Search" = "paid_search_touches",
"Display" = "display_touches",
"Social_Media" = "social_touches"
)
)
# Finally, I'll fill in any NAs with 0
touch_combo_conv_rate = touch_combo_conv_rate %>%
mutate_all(funs(ifelse(is.na(.),0,.))) %>%
mutate(
conv_rate = ifelse(total_sequences > 0, conversions/total_sequences, 0)
)
Once run, this code gives me a data frame that looks like this:
| Natural_Search | Affiliates | Paid_Search | Display | Social_Media | conversions | total_sequences | conv_rate | |
|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 | 0 | 55,437 | 1,084,028 | 0.0511 |
| 1 | 0 | 0 | 0 | 0 | 0 | 47,041 | 802,132 | 0.0586 |
| 0 | 1 | 0 | 0 | 0 | 0 | 14,894 | 450,189 | 0.0331 |
| 0 | 0 | 1 | 0 | 0 | 0 | 7,079 | 55,194 | 0.1283 |
| 0 | 0 | 0 | 1 | 0 | 0 | 4,577 | 112,297 | 0.0407 |
| 0 | 0 | 0 | 0 | 1 | 0 | 132 | 74,695 | 0.0018 |
| 0 | 0 | 0 | 0 | 0 | 1 | 134 | 1,528 | 0.0875 |
| 1 | 1 | 0 | 0 | 0 | 0 | 4,907 | 35,104 | 0.1340 |
| etc | etc | etc | etc | etc | etc | etc | etc | etc |
From here, I can now calculate all of the Shapley values I need for attribution weighting. Notice that I use the conversion rate as my “payoff” rather than the total conversions. I do this because usually, you’ll have fewer total conversions when multiple channels participate, but a higher conversion rate. Shapley values assume that when all “players” work together, the total payoff should be higher, not lower – so using the conversion rate makes the most sense as the payoff in this case.
# Building Shapley Values for each channel combination
shap_vals = as.data.frame(coalitions(number_of_channels)$Binary)
names(shap_vals) = c("Email","Natural_Search","Affiliates",
"Paid_Search","Display","Social_Media")
coalition_mat = shap_vals
shap_vals[2^number_of_channels,] = Shapley_value(touch_combo_conv_rate$conv_rate, game="profit")
for(i in 2:(2^number_of_channels-1)){
if(sum(coalition_mat[i,]) == 1){
shap_vals[i,which(shap_vals[i,]==1)] = touch_combo_conv_rate[i,"conv_rate"]
}else if(sum(coalition_mat[i,]) > 1){
if(sum(coalition_mat[i,]) < number_of_channels){
channels_of_interest = which(coalition_mat[i,] == 1)
char_func = data.frame(rates = touch_combo_conv_rate[1,"conv_rate"])
for(j in 2:i){
if(sum(coalition_mat[j,channels_of_interest])>0 &
sum(coalition_mat[j,-channels_of_interest])==0)
char_func = rbind(char_func,touch_combo_conv_rate[j,"conv_rate"])
}
shap_vals[i,channels_of_interest] =
Shapley_value(char_func$rates, game="profit")
}
}
}
After you’ve run this bit of code, if you inspect the resulting shap_vals data frame, you can see each of the Shapley values we’ll use for attribution. In a perfect world, you would never expect to see negative Shapley values, but in reality, I often do. This is because specific marketing channels can actually hurt the conversion rate. Why? Well, some marketing channels have a proclivity to bring in a lot of unqualified traffic. For example, it’s common for display ad click-throughs to be accidental, which means that if I see a visitor to my site from a display ad click-through, I can usually predict that that visitor will not convert. The Shapley values pick up on that fact and sometimes exhibit negative values in our matrix as a result.
Finally, I can multiply the resulting Shapley values by the number of sequences observed for each channel, and voila!
# Apply Shapley Values as attribution weighting order_distribution = shap_vals * touch_combo_conv_rate$total_sequences shapley_value_orders = t(t(round(colSums(order_distribution)))) shapley_value_orders = data.frame(mid_campaign = row.names(shapley_value_orders), orders = as.numeric(shapley_value_orders))
| mid_campaign | orders |
|---|---|
| 52,819 | |
| Natural_Search | 18,169 |
| Affiliates | 10,829 |
| Paid_Search | 6,049 |
| Social_Media | 180 |
| Display | 163 |
As you can see from my example dataset, the Shapley value method is relatively straightforward to implement, but it has a downside – Shapley values must be computed for every single marketing channel combination – 2^(number of marketing channels) in fact, which becomes unfeasible for more than about 15 channels. The next algorithmic method I’ll cover, while more difficult to implement yourself, doesn’t suffer from this drawback.
The Markov Chain Method
The Markov Chain approach has gained a lot of attention over the last few years, and there are tons of fantastic resources out there if you want to learn the statistics behind it including this article by Kaelin Harmon and this article by Sergey Bryl. At a high level, Markov chain advocates believe the best way to model attribution is by considering each marketing channel as a state in a Markov chain. So, if a visitor comes to the site via Email, they become part of the “Email state” which has an increased probability of conversion compared to someone who has not come into any marketing channel at all. Increases (or decreases) in conversion probability from this approach are then used as attribution weights to distribute conversions equitably.
Markov chains can be a pain to implement (especially at scale), but luckily for us, the “ChannelAttribution” R package written by Davide Altomare and David Loris makes this a lot easier. Once we have the sequences setup previously, it just requires one additional sparklyr step to prepare the data for modeling: creating a channel “stack.” A channel stack is where we take each step of the marketing channel journey for each sequence and concatenate it all together – for example, “Email > Display > Email > Natural Search” would describe a visitor moving from Email to Display, to Email again, then finally to Natural Search.
Channel stacks are simple enough to construct using the Spark function “concat_ws”. From there, I’ll filter out all of the paths that had no marketing channel touchpoints at all:
channel_stacks = data_feed_tbl %>%
group_by(visitor_id, order_seq) %>%
summarize(
path = concat_ws(" > ", collect_list(mid_campaign)),
conversion = sum(conversion)
) %>% ungroup() %>%
group_by(path) %>%
summarize(
conversion = sum(conversion)
) %>%
filter(path != "") %>%
collect()
Next, I’ll feed this data to the “markov_model” function, and it does the tricky part. One quick note about the “order” parameter – this sets the order of Markov chain you want to use. A higher order Markov chain computes probabilities based on not just the current state (a single marketing channel) but across several ordered states (combinations of channels) and assigns weighted probabilities to each combination. For example, the sequence Email > Display might have a different weight than Display > Email. Be careful not to set the Markov order too high, so you don’t overfit – typically I wouldn’t go beyond a 2nd or 3rd order Markov chain.
library(ChannelAttribution)
markov_chain_orders = markov_model(channel_stacks,
"path", "conversion", order=3)
names(markov_chain_orders) = c("mid_campaign", "orders")
markov_chain_orders$orders = round(markov_chain_orders$orders)
On my example dataset, this gives me an attribution of:
| mid_campaign | orders |
|---|---|
| 49,090 | |
| Natural_Search | 20,094 |
| Affiliates | 11,432 |
| Paid_Search | 7,055 |
| Display | 361 |
| Social_Media | 201 |
Unfortunately, the “ChannelAttribution” package doesn’t give a whole lot of information about its algorithm beyond the attribution outcome, which makes it a little harder to trust/validate in my opinion. Ideally, the markov_model function would allow you to input your own Markov transition matrix or at least inspect the transition matrix it creates based on the input data (to check the sanity of my data), but as of the time of this writing, I didn’t see an easy way to do that.
Lastly, the “ChannelAttribution” package would not be feasible when your channel stacks don’t fit into your machine’s memory. For huge datasets, you’d have to manually construct a Markov chain using Spark SQL or a sparklyr extension which is a little more effort than I’m willing to do for this blog post…
Pros and Cons of Each Method
So you may be left wondering, ok these both sound great – but which one should I be using? The answer (as usual for most machine learning problems) is: it depends on what assumptions you are most comfortable with.
I think the Shapley value method has a few advantages over the Markov chain method:
- It has much broader industry adoption and has been used successfully in attribution and auto-bidding platforms for years.
- It’s backed by Nobel Prize winning research.
- It takes a slightly more straightforward approach to the attribution problem in which sequence doesn’t matter – which makes it easier to implement and its results are usually more stable in practice.
- The results of the algorithm are also less sensitive to the input data.
That said, I think the Markov chain method outshines the Shapley value method in a few ways:
- It considers channel sequence as a fundamental part of the algorithm which is more closely aligned to a customer’s journey.
- It has the potential to scale to a more considerable number of channels than Shapley value can – marginal contributions for Shapley value must be calculated 2^n times (n being the number of marketing channels), which becomes pretty much impossible beyond 15 or 20 marketing channels.
- It can be applied not only to the marketing channel but potentially to the individual marketing campaign level which is more actionable for personalization.
To summarize, here are the results from all of the attribution models I’ve constructed thus far and their corresponding differences from the mean:
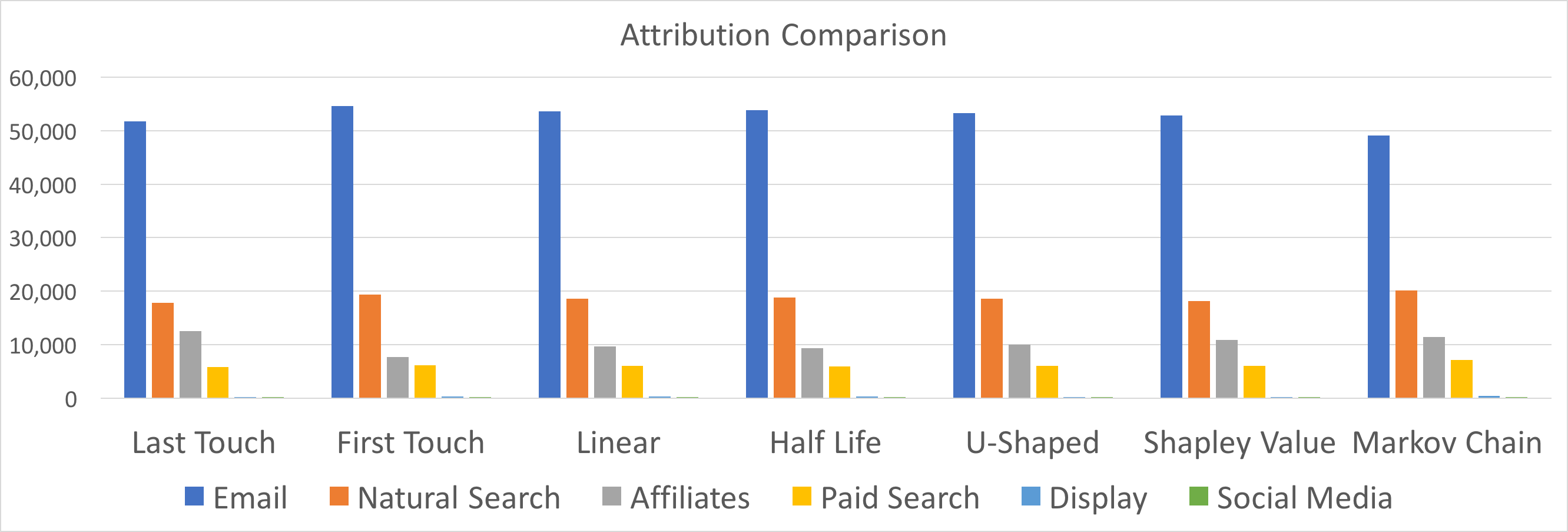
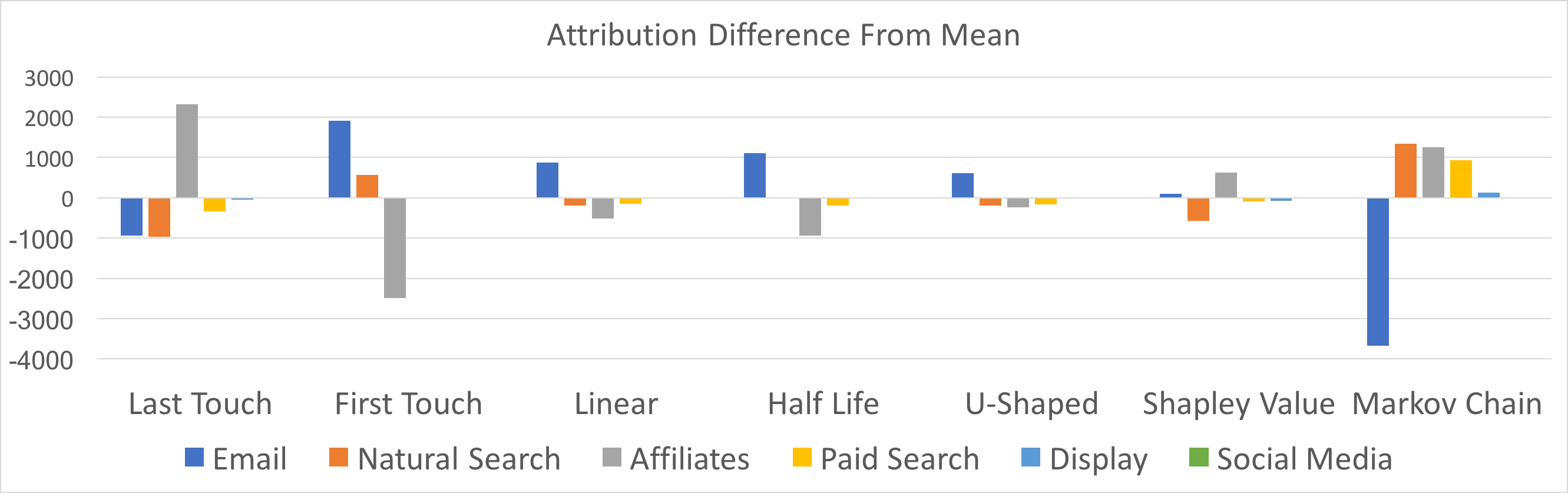
In conclusion, whichever method you prefer is undoubtedly better than heuristic models because it takes the human guesswork out of the equation. Hopefully, this post helps you in your efforts towards smarter attribution! Please feel free to respond with questions/comments on Twitter – I’d love to hear how you might be tackling similar problems.
Best of luck!
Nice post. Very detailed and good overview. How dependent do you think these results are on the specific data set used? What would be really interesting is to simulate over data sets with different properties to see how the various approaches diverge. To the degree that this dataset is representative, I would think that really this is arguing is to just do whatever approach is simplest, since the results are surprisingly consistent across all of the approaches. The rank order is the same across all results. Even in the case of the Markov model, the differences in the value estimates are only off by around 6 to 8%. Hard to see how any policy recommendation would differ based on the different approaches.
Hey Trevor,
Having trouble getting the code to compile. concat_ws isn’t present in sparklyr (at least my version), and I can’t seem to get SparkR to instal, so I’m curious if you’ve got a workaround/solution.
Totally agreed. In real life, typically less than 20% of order sequences have more than 1 touchpoint anyways, so these results are anecdotally typical; however, I agree a more thorough comparison is totally warranted. I’ve been wanting to do a follow-up post about that when I get some more time!
concat_ws is a Spark SQL function:
https://spark.apache.org/docs/2.2.0/api/java/org/apache/spark/sql/functions.html
So, you’ll have to rely on sparklyr to have that function work. For some reason, I couldn’t get “paste” to work in my example which is supposed to map to concat_ws, but might be worth a try in your case.
Hi Trevor,
could you please put somewhere example data set to play with your code ?
Thanks in advance
That’s an awesome idea! Let me see if I can figure something out – the datasets I work with are not always something I can just share publicly and the results I share in my posts are obfuscated (although representative of my real results).
It would be great if You can obfuscate them and publish some sample.
Really informative and thorough technical post, Trevor! And thanks very much for the link 🙂 Much appreciated!
Could you explain why you calculate shapley values in loop for smaller set of channels ? It is not enough to calculate them just for all ? You use it to deal with negative shapley values ?
No, thank you!
The loop above should work for any number of channels – just set the “number_of_channels” variable to whatever number you have.
I know that it works for given number of channels but I am curious why it is not enough to calculate them just one time for all channels like in this line: shap_vals[2^number_of_channels,] = Shapley_value(touch_combo_conv_rate$conv_rate, game=”profit”)
Hi Trevor,
great post – I learned a lot! According to my knowledge, the “markov_model” function does report the calculated transposition matrix based on the input data, you simply need to set the option “out_more” to true and you do get the $result, $transposition_matrix, and $removal_effects. Using this information you can validate your attribution findings.
Best Lars
Can I suggest that if you’re concerned about sharing a real data set, you can at least publish and example of the ‘structure’ of the original file (‘data_feed_tbl’) so we can recreate it with dummy data?
Very informational and illustrative, excellent post! My concern about attribution approach is that it lacks of “predictability”. As we know that marketing is all about ROI — I am afraid that there are no mathematical prove a maximum investment return if an advertiser reallocates marketing budget at time t+1 according to model result for time t.
Cool, I’ll have to give that a try. Thanks for the tip!
Hi Trevor, Nice article. FYI, if you set the out_more parameter in the markov_model(..), function call, you will get the transition matrix as well as removal probabilities as well.
https://www.rdocumentation.org/packages/ChannelAttribution/versions/1.13/topics/markov_model
Thanks, I’ll have to test it out!