
Follow @trevorwithdata Much has been said regarding the benefits of multi-touch or algorithmic attribution models to understanding your customers’ conversion paths, but running analyses merely looking at some numbers in a table doesn’t quite inspire insight in the same way that a well-constructed visualization can. So, in this post, I’m going to give you two great ways […]
Tag: sparklyr

Build Your Own Cross-Device Marketing Attribution with Apache Spark and R
Follow @trevorwithdata Over my last few posts I’ve been focusing on how to do better marketing attribution using Adobe Analytics Data Feeds and Apache Spark coupled with R. You can read all about those attribution techniques here: Multi-Touch Attribution Using Adobe Analytics Data Feeds and R The Two Best Models for Algorithmic Marketing Attribution That said, […]

Attribution Theory: The Two Best Models for Algorithmic Marketing Attribution – Implemented in Apache Spark and R
Follow @trevorwithdata In my last post, I illustrated methods for implementing rules-based multi-touch attribution models (such as first touch, last touch, linear, half-life time decay, and U-shaped) using Adobe Analytics Data Feeds, Apache Spark, and R. These models are indeed useful and appealing for analyzing the contribution any marketing channel has to overall conversions. However, they […]

Multi-Touch Attribution Using Adobe Analytics Data Feeds and R
Follow @trevorwithdata One of the hottest topics in the digital marketing space has always been marketing attribution. If you’re unfamiliar with this problem space, (I’d be surprised, but) there are lots of excellent explanations out there including this one. In a nutshell, companies have a lot of marketing outlets – search, display ads, social networks, email, […]

How to Use Classifications With Adobe Analytics Data Feeds and R
Follow @trevorwithdata Adobe Analytics Classifications is one of the most useful and popular features of Adobe Analytics, allowing you to upload meta-data to any eVar, prop, or campaign that you may be recording in Adobe Analytics. Classifications are useful when you need to do things like: Classify your marketing campaign tracking codes into their respective marketing […]

Propensity Scoring in Adobe Analytics Using Data Feeds and R
Follow @trevorwithdata When I was a kid, my favorite TV gameshow was “The Price Is Right” – it’s flashy, fun, and to this day I still love watching it – that is except for one thing: the ads. I still find it obnoxious to be bombarded by annoying (and sometimes gross) TV ads about hemorrhoid […]

Algorithmic Bot Filtering in Adobe Analytics Using R
Follow @trevorwithdata Over the last few years, I’ve noticed a marked increase in the number of companies that are worried about their analytics data becoming contaminated with non-human traffic – and with good reason. According to a fairly recent report from Imperva, websites that have more than 100k human visitors everyday should expect nearly one […]

Clustering Your Customers Using Adobe Analytics Data Feeds and R
Follow @trevorwithdata Theodore Levitt was a famous Harvard economist who is famous for his definition of corporate purpose, which he proposed was not merely making a profit, but instead creating and keeping customers. One of my favorite quotes comes from his book, The Marketing Imagination, in which Levitt says, “If you’re not thinking segments, you’re not thinking.” […]

Visitor Level Aggregations Using R and Adobe Analytics Data Feeds
Follow @trevorwithdata Visitor level aggregations (or as I like to call them, “visitor rollups”) are one of the most useful and meaningful things you can do with an Adobe Analytics data feed. If you ever want to do cluster analysis to find interesting marketing segments, propensity modeling to find likely converters, or product affinity analysis for cross […]
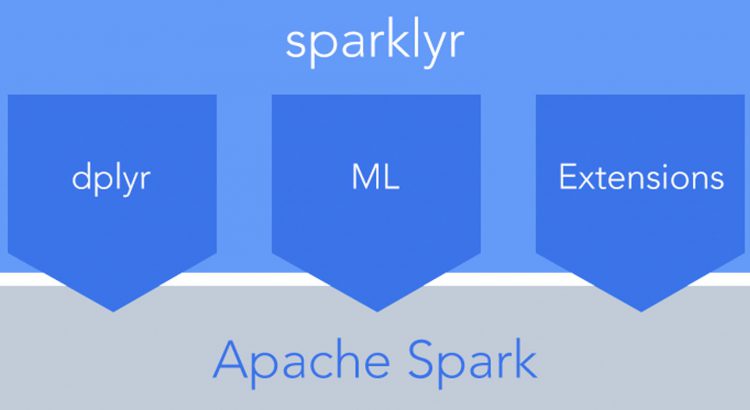
How to Setup sparklyr: An R Interface for Apache Spark
Follow @trevorwithdata If you haven’t heard of Apache Spark yet, I’d be pretty surprised. It’s an amazing open source project that’s changing the way people think about processing big data. That said, in my opinion it has never been super accessible to those of us data enthusiasts who aren’t Java application engineers – that is until […]