
Over my last few posts I’ve been focusing on how to do better marketing attribution using Adobe Analytics Data Feeds and Apache Spark coupled with R. You can read all about those attribution techniques here:
- Multi-Touch Attribution Using Adobe Analytics Data Feeds and R
- The Two Best Models for Algorithmic Marketing Attribution
That said, I’ve intentionally neglected to talk about one of the most complicated and tricky aspects of doing proper marketing attribution: cross-device attribution. According to Global Web Index, digital consumers own 3.64 connected devices on average. For me, it’s way higher. I own an iPhone, an iPad, a work laptop, a family PC, an Apple TV, a Roku, an Apple Watch, a Nintendo Switch, and a PlayStation 4. I get digital marketing in some form or another on all nine of them and have made digital purchases on all nine as well. Translation: if your attribution efforts are not cross-device, your attribution models are probably pretty wrong.
As complicated and sophisticated as attribution models can be, establishing customer identity for attribution purposes is far more difficult in my opinion, which is why I haven’t written about it until now. There are two significant reasons why cross-device attribution is so tricky: 1) it’s technically complex and computationally expensive (that’s why companies like Tapad and Drawbridge make good money), and 2) you need to be careful to respect your customers’ privacy and make sure you don’t run afoul of privacy regulations. But with consideration for these two issues, we’ll try to tackle each of these topics in this blog post.
So, before we begin, I want to call out a couple of things:
- I’m not a lawyer. So even though I’m pretty familiar with most privacy regulations, don’t take my advice as legal advice. Privacy regulations vary a lot by country; make sure you have a real attorney review anything you’re doing that you believe might even be close to violating privacy regulations in your area (especially if you live in an area impacted by GDPR).
- The queries we’re going to use are pretty taxing on CPU and memory, so make sure you have adequate resources for the job. If you have massive amounts of data (like in the hundreds of millions of visitors per month), fair warning: you might want to double check with your IT manager before trying these queries lest you rack up a monster AWS or Azure bill…
To do cross-device analysis, you’ll need to have at least one of these things available within your data:
- A customer identifier (typically a CRM ID or hashed email address for example). If you’re storing unhashed email addresses (or other personal data) in your Analytics data, please be careful (I would also advise that you stop doing that, but again I’m not a lawyer). Moving personal data around or insecurely storing it can be a significant risk.
- If you don’t have a customer identifier, and you live in an area where it’s ok to store an unobfuscated IP address (like the USA), I’ll show you how you can use that too. Again, you’ll need to be careful here. Using an IP address as a cross-device customer identification method might require that you update your site or app’s privacy policy (among other things).
With that in mind, the way we’ll accomplish cross-device attribution will follow two steps: combining the visitor (cookie/device) IDs from the same IP addresses, then splitting/rejoining/merging all of those device/IP IDs based on the customer IDs in the data.
Step 1: Combining Devices Using IP Address
Not everyone is comfortable using IP address as a method of customer identification. First, it’s not totally accurate – there’s no guarantee that two devices on the same IP address are from the same person. Second, you can inadvertently combine a lot of devices if you don’t establish some limits – for example, you might accidentally treat everyone in a single office building or college campus as one person (aside from being bad for your attribution, you’ll want to avoid that for computational reasons). Third, it may not be possible to use IP addresses if you’ve obfuscated them during data collection (typically a default setting for Adobe Analytics); or fourth, for privacy reasons, you may want to avoid using IP address altogether. So if any of these nuances bother you, feel free to skip this step; but remember if your company doesn’t really have a customer ID, or your login rate is woefully low, this may be the only thing you can do.
I’ll assume you’ve got your data already loaded into a sparklyr data frame, and that your column with IP address is called “ip,” and your visitor/cookie ID is in a column called “visitor_id” (see my previous posts on how to get this setup). The first thing we’re going to do is locate all of the IP addresses that have more than one cookie ID (useful for stitching cookies) and less than twenty cookie IDs (an arbitrary number I picked to prevent over-stitching):
ips_to_use = data_feed_tbl %>% group_by(ip) %>% summarize( visitors = n_distinct(visitor_id) ) %>% filter(visitors <= 20 & visitors > 1)
Next, I’ll need to identify all of the visitor IDs that these IP addresses apply to. This is a little trickier than it sounds because a single visitor ID can have multiple IP addresses (say if someone takes their laptop from work to home). To deal with this, I’m just going to grab the most recent IP address a visitor ID had, then left join the previous list of IPs I created to it to form a new set of visitor IDs for my basis of attribution:
visitor_ip_lookup = data_feed_tbl %>%
group_by(visitor_id) %>%
arrange(hit_time_gmt) %>%
summarize(
last_known_ip = last_value(ip)
) %>% ungroup() %>%
left_join(ips_to_use, by=c("last_known_ip"="ip")) %>%
mutate(
new_visitor_id = ifelse(is.na(visitors), visitor_id, last_known_ip)
)
Using this approach, it’s not uncommon to combine roughly 20% to 40% of the total devices in your data into a single visitor based on my experience – not too shabby! To finish this step, we’ll join the new_visitor_id to my original dataset before moving on to the next step (or skipping straight down to the attribution itself):
data_feed_tbl = data_feed_tbl %>% left_join(visitor_ip_lookup, by="visitor_id")
To illustrate what I’ve just done, I’ve created a new column called “new_visitor_id” that has replaced any visitor_id with an IP address, so long as that IP address appeared on twenty or fewer visitors, and appeared on two or more visitors:
| visitor_id | ip_address | new_visitor_id |
|---|---|---|
| 1234 | 1.2.3.4 | 1.2.3.4 |
| 1234 | 1.2.3.4 | 1.2.3.4 |
| 1234 | 1.2.3.4 | 1.2.3.4 |
| abcd | 1.2.3.4 | 1.2.3.4 |
| abcd | 1.2.3.4 | 1.2.3.4 |
| wxyz | 4.3.2.1 | wxyz |
| wxyz | 4.3.2.1 | wxyz |
| 5678 | 5.6.7.8 | 5678 |
Now I have a new visitor ID in the dataset that I’ll use as a basis for attribution. For further device stitching based on a customer ID, continue to the next step.
Step 2: Combining Devices Using a Customer ID
Using a customer ID can get pretty confusing. While a single person typically uses multiple devices, often a single device is shared by numerous people. This multiple people to multiple devices relationship makes using a customer ID for cross-device attribution really messy because we’ll have to split one device into multiple attribution entities if it has multiple customer IDs, then combine those entities across other devices with the same customer ID… yuck. (If I’ve lost you – just hang on, I’ll explain).
Here’s an example to explain what I mean: For Christmas last month I was trying to find just the right gift for my wife – I was searching for gifts on my phone, on my work laptop, and on our family office computer (using my account). My wife, on the other hand, was searching for gifts for our kids on her phone and on our family computer (using her account). Ideally, for marketing purposes, you’d want to consider my phone, my work laptop, and the sessions I had on our family computer as “me” (one attribution entity), and my wife’s phone and the sessions she had on our family computer as “her” (another attribution entity). To be accurate, I need to find a way to split up the sessions on our family computer and combine them with the other devices/sessions where appropriate.
Before we start, just a couple of pointers based on my own experience:
- If you’re using an email address as a customer ID, make sure to lowercase that field and remove all the periods first. This ensures you don’t treat tre.vor@example.com any differently from Trevor@example.com.
- You can make these modifications easily using the mutate function from sparklyr and the regexp_replace function from Spark SQL.
To split one device (or IP address) with multiple customer IDs, I’m going to group by the new_visitor_id I created previously (or just use visitor_id if you skipped step 1), and using some clever windowing functions, I’ll split up all of the hits amongst the customer IDs I observed – creating a new column “id_group” using my customer ID column, “user_id”.
temp_id = data_feed_tbl %>%
group_by(new_visitor_id) %>%
arrange(-hit_time_gmt) %>%
mutate(id_group = ifelse(!is.na(user_id), 1, NA)) %>%
mutate(id_group = lag(cumsum(ifelse(is.na(id_group), 0, id_group)))) %>%
mutate(id_group = ifelse((row_number() == 1) & !is.na(user_id), -1,
ifelse(row_number() == 1, 0, id_group))) %>%
ungroup()
Now, I can use the id_group column as a basis for joining the applicable customer IDs for each id_grouping. Next, I’ll need to create a lookup table so I can actually do that join:
id_lookup = temp_id %>%
group_by(new_visitor_id, id_group) %>%
summarize(
merged_id = concat_ws("", collect_list(user_id))
) %>% ungroup() %>%
group_by(new_visitor_id) %>%
arrange(id_group) %>%
mutate(
lagged_merged_id = lag(merged_id),
merged_id = ifelse((merged_id == "") &
(id_group == max(id_group)), lagged_merged_id, merged_id)
) %>%
mutate(
merged_id = ifelse(is.na(merged_id), new_visitor_id, merged_id)
) %>%
select(
new_visitor_id,
id_group,
merged_id
)
After running that bit of code, I can finally do the join:
new_id = temp_id %>%
left_join(id_lookup, by=c("new_visitor_id","id_group"))
Finally, my merged visitor ID should look something like this as an example:
| (new_)visitor_id | user_id | hit_time_gmt | id_group | merged_id |
|---|---|---|---|---|
| 1234 | 1 | 0 | trevor@example.com | |
| 1234 | 2 | 0 | trevor@example.com | |
| 1234 | trevor@example.com | 3 | 1 | trevor@example.com |
| 1234 | 4 | 1 | trevor@example.com | |
| 5678 | trevor@example.com | 5 | 0 | trevor@example.com |
| 5678 | 6 | 0 | trevor@example.com | |
| 5678 | jared@example.com | 7 | 1 | jared@example.com |
| 5678 | 8 | 1 | jared@example.com | |
| 91011 | 9 | 0 | 91011 | |
| 91011 | 10 | 0 | 91011 | |
| 91011 | 11 | 0 | 91011 |
And now, I finally have a cross-device set of IDs to use for attribution. If you’ve followed my previous posts on doing attribution models, you can now use any of the rules based or algorithmic attribution rules I’ve previously illustrated.
Tying It All Together
To wrap it up, I’ll run a comparison: an unstitched (not cross-device) last touch attribution versus a stitched (cross-device) last touch attribution to illustrate the benefits of cross-device attribution:
# Unstitched Last Touch Attribution (from my previous post):
nonstitched_dataset = data_feed_tbl %>%
group_by(visitor_id) %>%
arrange(hit_time_gmt) %>%
mutate(order_seq = ifelse(conversion > 0, 1, NA)) %>%
mutate(order_seq = lag(cumsum(ifelse(is.na(order_seq), 0, order_seq)))) %>%
mutate(order_seq = ifelse((row_number() == 1) & (post_event_list %regexp%
",1,"), -1, ifelse(row_number() == 1, 0, order_seq))) %>%
group_by(visitor_id, order_seq) %>%
mutate(
order_seq = ifelse(sum(conversion)>0, order_seq, NA)
) %>% ungroup() %>% ungroup()
attributable_sequences_unstitched = stitched_dataset %>%
filter(!is.na(mid_campaign) & !is.na(order_seq))
last_touch_orders_unstitched = attributable_sequences %>%
group_by(visitor_id, order_seq) %>%
top_n(1,hit_time_gmt) %>%
select(visitor_id, order_seq, mid_campaign) %>%
ungroup() %>%
group_by(mid_campaign) %>%
summarize(orders = n()) %>% collect()
# Stitched Last Touch Attribution (using the merged IDs from this post):
stitched_dataset = new_id %>%
group_by(merged_id) %>%
arrange(hit_time_gmt) %>%
mutate(order_seq = ifelse(conversion > 0, 1, NA)) %>%
mutate(order_seq = lag(cumsum(ifelse(is.na(order_seq), 0, order_seq)))) %>%
mutate(order_seq = ifelse((row_number() == 1) & (post_event_list %regexp%
",1,"), -1, ifelse(row_number() == 1, 0, order_seq))) %>%
group_by(merged_id, order_seq) %>%
mutate(
order_seq = ifelse(sum(conversion)>0, order_seq, NA)
) %>% ungroup() %>% ungroup()
attributable_sequences = stitched_dataset %>%
filter(!is.na(mid_campaign) & !is.na(order_seq))
last_touch_orders_stitched = attributable_sequences %>%
group_by(merged_id, order_seq) %>%
top_n(1,hit_time_gmt) %>%
select(merged_id, order_seq, mid_campaign) %>%
ungroup() %>%
group_by(mid_campaign) %>%
summarize(orders = n()) %>% collect()
# Comparing the two:
differences = last_touch_orders_unstitched %>%
left_join(last_touch_orders_stitched, by="mid_campaign")
Whew! Here’s the results I get on my sample dataset:
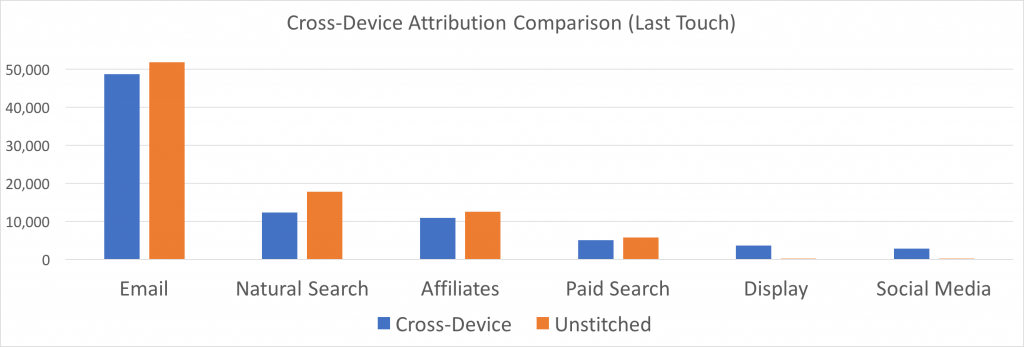
What’s most interesting is that you see Email, Natural Search, and Affiliates (traditionally my heaviest hitters) get a significantly smaller proportion of credit. Notice that Display and Social Media get a lot more credit as well – this says to me that a lot of people look at Social Media or Display ads on one device, but purchase on another which is a pretty significant insight!
Of course you can use any attribution model, including the fancier ones like Shapley Value or Markov Chain that I covered in my last blog post in conjunction with a cross-device approach, but hopefully even this last touch example is helpful in moving you down the path of a more accurate attribution strategy. In fact, you can also use this approach to do better visitor level aggregations, propensity models, cluster models, or even better marketing mix models.
Good luck, and please let me know if you thought this was useful (or anything else we’ve posted on this blog for that matter) on LinkedIn and Twitter!