
Adobe Clickstream Data Feeds are the most granular way to view your analytics data. They effectively contain all the information that Adobe Analytics needs to build its reports.
Having a good understanding of how to use these feeds will allow you to use Analytics data in ways that aren’t possible through LiveStream, the Web Services API, or the Analytics UI. Common use cases are:
- Creating dashboard reports for executives with visualization tools such as Tableau, Jupyter, d3.js, or Shiny R
- Creating custom integrations with other software platforms/clouds
- Analysis at a hit or visitor level using R, Python, Scala, Matlab or other tools
Data Feeds are hard to deal with because of their format. The documentation describes some of the nuances but doesn’t have all of the information you probably need to do deeper analysis. To make things even harder, data feeds look like a flat file but are in some cases actually storing relational data.
For example, the product list stores a list of product items in a customer’s shopping cart along with other lists of eVars and events that are set on each product item — all in the same field! The event IDs reference a separate lookup table that’s bundled with the data feed.
In this post, I hope to provide some insight into how you can squeeze as much information out of data feeds as possible. To do this, I’m going to cover a bunch of different tips over a few different posts, but in this post I’m going to focus on dealing with special characters in Data Feeds – the most common problem I hear about from people using Data Feeds.
To understand why special characters can cause issues, you have to realize that whenever data is sent into Adobe Analytics, it records it all. For example, if you place text that contains a tab or newline character in an eVar, it gets saved in Analytics, verbatim. This can create a problem for processing Data Feeds, which have tab-separated columns and new-line separated records.
Special characters are usually the first problem that most people have when processing Data Feeds. When loading data into a database or other data warehousing system, the parsing code chokes on unexpected tabs/newlines in the file.
Special characters are handled by Data Feeds using escape characters. Escaped characters are always proceeded by a ‘\’ character indicating that this tab or newline isn’t used to format the data feed file, but is actually part of the data.
In my experience, special characters typically appear in your data if you’re storing user generated text into an eVar – like search terms or other user input text fields. Oftentimes, foreign languages with non-Latin characters can also add escaped characters in your data as well.
There are three ways to handle special characters in Data Feeds:
Write Code to Correctly Parse the Data
Parse the characters so that your platform (Redshift, Hive, etc) understands that they are part of the data and not to be used for formatting. This usually requires writing code or scripts to import the data. As a result, this is the most difficult option of the three discussed in this post, but doesn’t modify the content of data feeds at all.
Replace Special Characters with Spaces (or some other character of your choosing)
You can write a program that reads through all of the data in each data feed file and replaces special characters with something a little more benign. I’ve created a short Java application that can be run from the command line for simplicity. There is a lot of room for optimization but wanted to use clear methods for reading and processing the data. I’ve tried to keep it simple to make it easier to port to other languages. The full project is available in GitHub here.
String inputFile = "TestFile.txt";
FileInputStream in = null;
System.out.println("Processing file: " + inputFile);
in = new FileInputStream(inputFile);
int c1, c2;
// Read in the first byte
c1 = in.read();
while (true) {
// If the file is empty, quit.
if (c1 == -1) break;
// If we find an escape character,
// read the next byte to see if its one of our
// special characters.
if (c1 == 92) {
c2 = in.read();
// Let's break out of our loop if there is no next
// character
if (c2 == -1) break;
if (c2 == 9 || c2 == 10 || c2 == 13) {
// Oooooh. The next character is a tab or newline!
// Replace it with a space!
System.out.print((char) 32);
} else if (c2 == 92) {
// We found an escaped '\'.
// Print a single '\'.
System.out.print((char) 92);
} else {
// The next character isn't anything interesting
// Print out the backslash character
System.out.print((char) c1);
// Since we've already read the next byte,
// let's do the following:
// 1. Set c1 to c2 (the value in c2 is the next byte)
// 2. Skip the rest of the loop
// so that we don't read/print an extra byte
c1 = c2;
continue;
}
} else {
System.out.print((char) c1);
}
c1 = in.read();
}
Here are the results of the test file after this code has been executed:
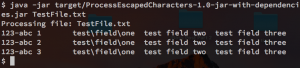
Note how the escaped tabs and newlines are gone and the escaped backslashes were replaced with a single bash slash. You don’t have to use spaces — it would be trivial to replace escaped characters with underscores as well. This code is also a good starting point for writing the custom input code mentioned in the first option.
Use the Data Feed Request Tool to Replace Characters For You
When setting up your Data Feed (you can find our guide on setting up Data Feeds here), make sure to enable the “Remove Escaped Characters” setting as part of the Data Feed configuration. This works for almost all use cases, but provides the least flexibility of the three options here. That being said, I rarely hear of this not working. To set this up, just check the box on the left when setting up your Data Feed:
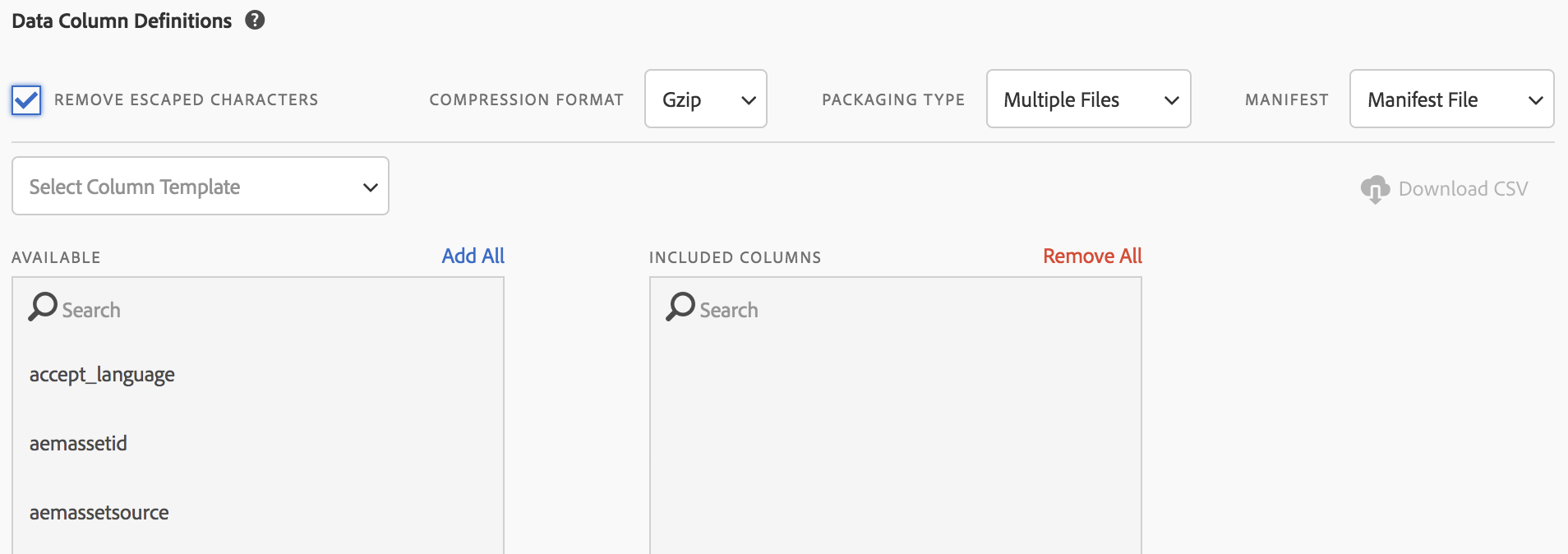
If you’re working with data feeds that were created by Customer Care, you can call them up and have them check a similar box within their internal tool.
For more resources on dealing with special characters and Java I/O you can check out these links:
Good luck, and come back for more helpful tips on dealing with Adobe Analytics Data Feeds.
Jared,
We are using the Adobe Report API (rest API) to run reports and bring back report data. Is there any setting within the API’s that we can use to suppress the backslash (\)? Thanks… Ted
Hi Ted — Sorry for the late response. Unfortunately, there isn’t. I’m aware of how annoying that is as I’ve had to deal with it myself. There are newer APIs coming (the same ones that the Analysis Workspace UI uses) that will follow JSON encoding rules for escaped characters. That will hopefully clear up this problem.